Tests
In this chapter
This chapter provides a theoritical overview of all the tests available in JDemetra+, via Graphical User Interface and R packages.
Tests on residuals
| Test | Purpose | GUI display | GUI output | Cruncher output | R standalone | R in SA estimation |
|---|---|---|---|---|---|---|
| Ljung-Box | autocorrelation | ✔️ | ✔ | ✔ | rjd3toolkit | rjd3x13 / rjd3tramoseats |
| Doornik-Hansen | normality | ✔️ | ✔ | ✔ | rjd3toolkit | rjd3x13 / rjd3tramoseats |
| Skewness | skewness | ✔ |
Ljung-Box
For R code estimation object is obtained as
The Ljung-Box Q-statistics given by :
\[ \text{LB}(K)=n \times (n+2) \times \sum_{j=1}^{K}\frac{\hat\rho_{a,j}^{2}}{n-j} \]
where \(\hat\rho_{j,k}^{2}\) is the sample autocorrelation coefficient at lag \(j\) of the residuals \(\widehat{a}_{t}\), \(n\) is the number of terms in the differenced series. \(K\) is the number of lags being considered, in JDemetra+ \(K=24\) for a monthly series and \(K=8\) for a quarterly series.
If the residuals are random (which is the case for residuals from a well specified model), \(\widehat{\rho}\) will be distributed as \(\chi_{(K-m)}^{2}\), where \(m\) is the number of parameters in the model which has been fitted to the data.
Dornik-Hansen
The Doornik-Hansen test for multivariate normality (DOORNIK, J.A., and HANSEN, H. (2008)) is based on the skewness and kurtosis of multivariate data that is transformed to ensure independence.
The skewness and kurtosis are defined, respectively, as: \(s=\frac{m_{3}}{\sqrt{m_{2}}^{3}}\) and \(k=\frac{m_{4}}{m_{2}^{2}}\),
where:
\(m_{i}=\frac{1}{n}\sum_{i=1}^{n}{(x_{i}}{-\overline{x})}^{i}\) ;
\(\overline{x}=\frac{1}{n}\sum_{i=1}^{n}x_{i}\) ;
\(n\) number of (non-missing) residuals.
The Doornik-Hansen test statistic derives from SHENTON, L.R., and BOWMAN, K.O. (1977) and uses transformed versions of skewness and kurtosis.
The transformation for the skewness \(s\) into \(\text{z}_{1}\) is as in D’AGOSTINO, R.B. (1970):
\[ \beta=\frac{3(n^{2}+27n-70)(n+1)(n+3)}{(n-2)(n+5)(n+7)(n+9)} \]
\[ \omega^{2}=- 1+\sqrt{2(\beta-1)} \]
\[ \delta=\frac{1}{\sqrt{\log{(\omega}^{2})}} \]
\[ y=s\sqrt{\frac{(\omega^{2}-1)(n+1)(n+3)}{12(n-2)}} \]
\[ z_{1}=\delta log(y+\sqrt{y^{2}-1}) \]
The kurtosis \(k\) is transformed from a gamma distribution to \(\chi^{2}\), which is then transformed into standard normal \(z_{2}\) using the Wilson-Hilferty cubed root transformation:
\[ \delta=(n-3)(n+1)(n^{2}+15n-4) \]
\[ a=\frac{(n-2)(n+5)(n+7)(n^{2}+27n-70)}{6\delta} \]
\[ c=\frac{(n-7)(n+5)(n+7)(n^{2}+2n-5)}{6\delta} \]
\[ l= \frac{(n+5)(n+7)({n^{3}+37n}^{2}+11n-313)}{12\delta} \]
\[ \alpha=a+c \times s^{2} \]
\[ \chi=2l(k-1-s^{2}) \]
\[ z_{2}=\sqrt{9\alpha}(\frac{1}{9\alpha}-1+\sqrt[3]{\frac{\chi}{2\alpha}}) \]
Finally, the Doornik-Hansen test statistic is defined as the sum of squared transformations of the skewness and kurtosis. Approximately, the test statistic follows a \(\chi^{2}\) distribution, i.e.:
\[ DH=z_{1}^{2}+z_{2}^{2}\sim\chi^{2}(2) \]
Skewness Test
from cruncher, is part of the Doornik Hansen
Seasonality tests
| Test | Purpose | Display GUI | R package |
|---|---|---|---|
| QS test | Autocorrelation at seasonal lags | ✔️ | |
| F-test with seasonal dummies | Stable seasonality | ✔️ | rjd3toolkit |
| Canova-Hansen | Seasonal frequencies | ✖ | rjd3toolkit |
| Identification of spectral peaks | Seasonal frequencies | ✔️ | |
| Friedman test | Stable seasonality | ✔️ | rjd3toolkit |
| Two-way variance analysis | Moving seasonality | ✔️ |
QS Test on autocorrelation at seasonal lags
The QS test is a variant of the Ljung-Box test computed on seasonal lags, where we only consider positive auto-correlations
More exactly,
\[ QS=n(n+2)\sum_{i=1}^k\frac{[\max(0, \hat\gamma_{i \cdot l})]^2}{n-i \cdot l} \]
where \(k=2\), so only the first and second seasonal lags are considered. Thus, the test would check the correlation between the actual observation and the observations lagged by one and two years. Note that \(l=12\) when dealing with monthly observations, so we consider the autocovariances \(\hat\gamma_{12}\) and \(\hat\gamma_{24}\) alone. In turn, \(k=4\) in the case of quarterly data.
Under H0, which states that the data are independently distributed, the statistics follows a \(\chi(k)\) distribution. However, the elimination of negative correlations makes it a bad approximation. The p-values would be given by \(P(\chi^{2}(k) > Q)\) for \(k=2\). As \({P(\chi}^{2}(2)) > 0.05=5.99146\) and \({P(\chi}^{2}(2)) > 0.01=9.21034\), \(QS > 5.99146\) and \(QS > 9.21034\) would suggest rejecting the null hypothesis at \(95\%\) and \(99\%\) significance levels, respectively.
Maravall (2012) proposes approximate the correct distribution (p-values) of the QS statistic using simulation techniques. Using 1000K replications of sample size 240, the correct critical values would be 3.83 and 7.09 with confidence levels of \(95\%\) and \(99\%\), respectively (lower than the 5.99146 and 9.21034 shown above). For each of the simulated series, he obtains the distribution by assuming \(QS=0\) when \(\hat\gamma_{12}\), so in practice this test will detect seasonality only when any of these conditions hold:
Statistically significant positive autocorrelation at lag 12
Non-negative sample autocorrelation at lag 12 and statistically significant positive autocorrelation at lag 24
F-test on seasonal dummies
The F-test on seasonal dummies checks for the presence of deterministic seasonality. The model used here uses seasonal dummies (mean effect and 11 seasonal dummies for monthly data, mean effect and 3 for quarterly data) to describe the (possibly transformed) time series behaviour.
The test statistic checks if the seasonal dummies are jointly statistically not significant. When this hypothesis is rejected, it is assumed that the deterministic seasonality is present.
This test refers to Model-Based χ2 and F-tests for Fixed Seasonal Effects proposed by LYTRAS, D.P., FELDPAUSCH, R.M., and BELL, W.R. (2007) that is based on the estimates of the regression dummy variables and the corresponding t-statistics of the RegARIMA model, in which the SARIMA part of the model as one of the following forms:
(0 1 0)(0 0 0)
(1 0 0)(0 0 0)
(0 0 0)(0 0 0)
In that way, the model can always be quickly estimated by a simple OLS. The first form will be the default for original series and for seasonally adjusted series. The last form is reserved for tests on irregular components and on residuals. Using more complex ARIMA models does not significantly change the results.
For instance, in the case of a monthly series and structure (0 1 0)(0 0 0), the RegARIMA model structure is as follows:
\[ (1-B)(y_{t}-\beta_{1}M_{1,t}-\ldots-\beta_{11}M_{11,t}-\gamma X_{t})=\mu+a_{t} \tag{1}\]
where:
\(M_{j,t} =\begin{cases}1 & \text{in month } j=1, \ldots, 11 \\- 1 & \text{in December}\\0 & \text{otherwise}\end{cases} \text{-dummy variables;}\)
\(y_{t}\) – the original time series;
\(B\) – backshift operator;
\(X_{t}\) – other regression variables used in the model (e.g. outliers, calendar effects, user-defined regression variables, intervention variables);
\(\mu\) – mean effect;
\(a_{t}\) – white-noise variable with mean zero and a constant variance.
The consequences of a misspecification of a model are discussed in LYTRAS, D.P., FELDPAUSCH, R.M., and BELL, W.R. (2007).
One can use the individual t-statistics to assess whether seasonality for a given month is significant, or a chi-squared test statistic if the null hypothesis is that the parameters are collectively all zero. The chi-squared test statistic is \({\widehat{\chi}}^{2}={\widehat{\beta}}^{'}{[ Var(\widehat{\beta})}^{\ })^{- 1}]{\widehat{\beta}}^{\ }\) in this case compared to critical values from a \(\chi^{2}(\text{df})\)-distribution, with degrees of freedom \(df=11\) (monthly series) or \(df=3\) (quarterly series). Since the \(Var(\widehat{\beta})\) computed using the estimated variance of \(\alpha_{t}\) may be very different from the actual variance in small samples, this test is corrected using the proposed \(\text{F}\) statistic:
\[ F=\frac{{\widehat{\chi}}^{2}}{s-1} \times \frac{n-d-k}{n-d} \]
where \(n\) is the sample size, \(d\) is the degree of differencing, s is time series frequency (12 for a monthly series, 4 for a quarterly series) and \(k\) is the total number of regressors in the Reg-ARIMA model (including the seasonal dummies \(\text{M}_{j,t}\) and the intercept).
This statistic follows a \(F_{s-1,n-d-k}\) distribution under the null hypothesis.
Friedman test for stable seasonality
The Friedman test is a non-parametric method for testing that samples are drawn from the same population or from populations with equal medians. The significance of the month (or quarter) effect is tested. The Friedman test requires no distributional assumptions. It uses the rankings of the observations. If the null hypothesis of no stable seasonality is rejected at the 0.10% significance level then the series is considered to be seasonal and the test’s outcome is displayed in green.
The test statistic is constructed as follows. Consider first the matrix of data \(\{x_{ij}\}_{n \times k}\) with \(n\) rows (the blocks, i.e. number of years in the sample), \(k\) columns (the treatments, i.e. either 12 months or 4 quarters, depending on the frequency of the data).
The data matrix needs to be replaced by a new matrix \(\{r_{ij}\}_{n \times k}\), where the entry \(r_{ij}\) is the rank of \(x_{ij}\) within block \(i\) .
The test statistic is given by
\[ Q=\frac{SS_t}{SS_e} \]
where \(SS_t=n \sum_{j=1}^{k}(\overline{r}_{.j}-\overline{r})^2\) and \(SS_e=\frac{1}{n(k-1)} \sum_{i=1}^{n}\sum_{j=1}^{k}(r_{ij}-\overline{r})^2\). It represents the variance of the average ranking across treatments j relative to the total.
Under the hypothesis of no seasonality, all months can be equally treated. For the sake of completeness:-\(\overline{r}*{.j}\) is the average ranks of each treatment (month) j within each block (year)-The average rank is given by \(\overline{r}=\frac{1}{nk}\sum_{i=1}^{n}\sum_{j=1}^{k}r_{ij}\)
For large \(n\) or \(k\) , i.e. \(n > 15\) or \(k > 4\), the probability distribution of \(Q\) can be approximated by that of a chi-squared distribution. Thus, the p-value is given by \(P(\chi^2_{k-1}>Q)\).
Moving seasonality test
The evolutive seasonality test is based on a two-way analysis of variance model. The model uses the values from complete years only. Depending on the decomposition type for the Seasonal/Irregular component it uses Equation 1 (in the case of a multiplicative model) or Equation 2 (in the case of an additive model):
\[ |\text{SI}_{\text{ij}}-1|=X_{\text{ij}}=b_{i}+m_{j}+e_{\text{ij}} \]
\[ |\text{SI}_{\text{ij}}|=X_{\text{ij}}=b_{i}+m_{j}+e_{\text{ij}} \]
where:
\(m_{j}\) – monthly or quarterly effect for \(j\)-th period, \(j=(1,\ldots,k)\), where \(k=12\) for a monthly series and \(k=4\) for a quarterly series;
\(b_{j}\) – annual effect \(i\), \((i=1,\ldots,N)\) where \(N\) is the number of complete years;
\(e_{\text{ij}}\) – residual effect.
The test is based on the following decomposition:
\[ S^{2}=S_{A}^{2}+S_{B}^{2}+S_{R}^{2}, \tag{2}\]
where:
\(S^{2}=\sum_{j=1}^{k}{\sum_{i=1}^{N}({\overline{X}}_{\text{ij}}-{\overline{X}}_{\bullet \bullet})^{2}}\) –the total sum of squares;
\(S_{A}^{2}=N\sum_{j=1}^{k}({\overline{X}}_{\bullet j}-{\overline{X}}_{\bullet \bullet})^{2}\) – the inter-month (inter-quarter, respectively) sum of squares, which mainly measures the magnitude of the seasonality;
\(S_{B}^{2}=k\sum_{i=1}^{N}({\overline{X}}_{i \bullet}-{\overline{X}}_{\bullet \bullet})^{2}\) – the inter-year sum of squares, which mainly measures the year-to-year movement of seasonality;
\(S_{R}^{2}=\sum_{i=1}^{N}{\sum_{j=1}^{k}({\overline{X}}_{\text{ij}}-{\overline{X}}_{i \bullet}-{\overline{X}}_{\bullet j}-{\overline{X}}_{\bullet \bullet})^{2}}\) – the residual sum of squares.
The null hypothesis \(H_{0}\) is that \(b_{1}=b_{2}=...=b_{N}\) which means that there is no change in seasonality over the years. This hypothesis is verified by the following test statistic:
\[ F_{M}=\frac{\frac{S_{B}^{2}}{(n-1)}}{\frac{S_{R}^{2}}{(n-1)(k-1)}} \]
which follows an \(F\)-distribution with \(k-1\) and \(n-k\) degrees of freedom.
Combined seasonality test
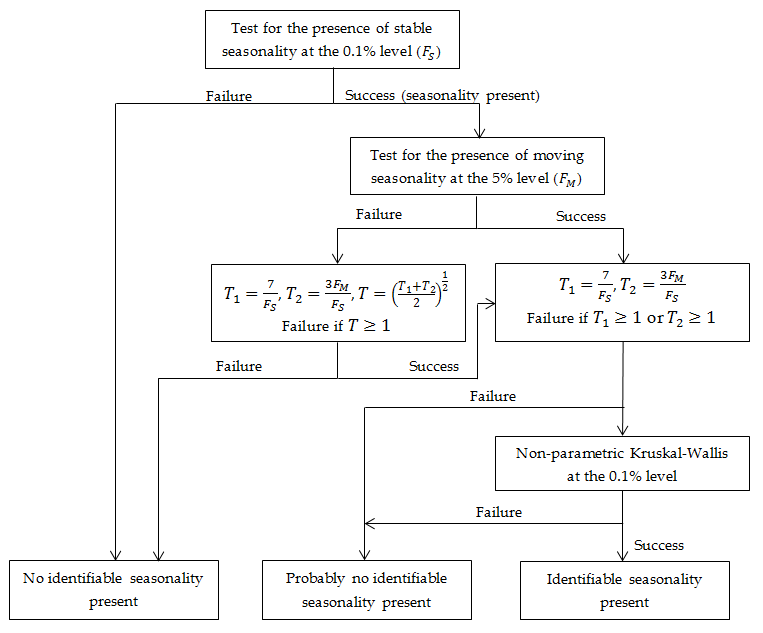
This test combines the Kruskal-Wallis test along with test for the presence of seasonality assuming stability (\(F_{S}\)), and evaluative seasonality test for detecting the presence of identifiable seasonality (\(F_{M}\)). Those three tests are calculated using the final unmodified SI component. The main purpose of the combined seasonality test is to check whether the seasonality of the series is identifiable. For example, the identification of the seasonal pattern is problematic if the process is dominated by highly moving seasonality (DAGUM, E.B. (1987)). The testing procedure is shown in the figure below.
Identification of spectral peaks
Tests related to identification of spectral peaks in a periodogram, autoregressive spectrum or Tuckey spectrum are detailed here in the chapter dedicated to spectral analysis.